In this guide, we will explore how to implement sharding with Lucene and Hibernate Search in a Spring boot and JPA environment. We will discuss why is it useful and when is it a good idea to implement it.
I would also suggest that you read our guide here if you are just getting started with Spring boot and Hibernate search.
What is sharding in Lucene?
When you configure a JPA entity for indexing, Lucene will create an index file for that entity. By default, all indexing data of that entity will be stored in a single index file.
On the other hand, “Sharding” involves splitting that index data file into multiple smaller ones. Each of these files is called a “Shard”, hence the name. Lucene will choose a strategy to store the data of specific entities in specific index files. For example, it can be that based on the entity’s id, the entity data will be stored in the first shard or the second shard, etc..
The strategy with which the shard file is chosen per entity is configurable, however, the default behavior is usually enough for most use cases.
What are the benefits of sharding and when is it useful?
As mentioned in the previous section, by default, Lucene will use one file per entity to store all the index data. The issue arises from the fact that Lucene needs to recreate the full index file when updates are made. During an update cycle, it does not matter if only one entry was updated or 100; the full index file will be rewritten.
Usually, this is not an issue as Lucene has become increasingly efficient in read/write operations. However, your application’s performance start to degrade once the number of indexed entries start to reach very large numbers.
Imagine for example a bank with a transactions table. Each day, tens of thousands of transactions occur. Imagine that you would need to re-index millions of entries. Not only that you will have your indexed data stored in a single file, which could reach gigabytes of size, but also that single file needs to be recreated every time the index is updated.
This is when sharding comes to the rescue. If your data is divided among 2 index files, instead of 1, only the shard that contains the data of the updated entry is recreated. There are two advantages to this approach:
- Splitting your index into multiple shards allows you to take advantage of your idle system resources. For example, if you see that you have a large application I/O, but low utilization of system resources such as CPU and disk usage, then by increasing the number of shards, you also increase the number of Lucene threads that are doing index read/write operations, and hence increasing the utilization of your disk usage as well.
- In case of infrequent write operations to the index, re-writing the smaller individual index files can theoretically be faster than recreating the larger files.
Please note that you will probably not see performance improvements with sharding, if you already experience hardware I/O bottlenecks without sharding. You might even degrade performance as sharding does incur an overhead. So feel free to experiment before deciding that sharding is for your system.
Configuring the sharded index
Remember in our previous tutorial, the indexed entity produced only one index directory:
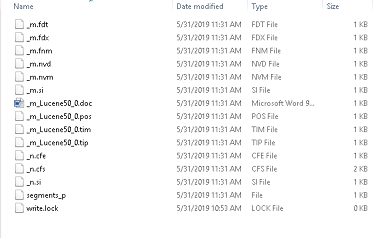
In Hibernate search, index settings can be configured either per index, or by have a fallback setting in case no specific configuration for a specific index is available.
Fallback configuration settings can be modified by adding properties with the index name default to your application.properties file. To prefix for Hibernate search’s JPA properties is hibernate.search. To put it all together, let us check the following settings from our Spring boot application:
spring.jpa.properties.hibernate.search.default.directory_provider=filesystem
spring.jpa.properties.hibernate.search.default.indexBase=./data
We previously created an entity class called “Person”. The class resided in the package com.nullbeans.persistence.models. In order edit the index settings of this specific entity, instead of the default index, we will need to use the class name, including the package name in the application properties.
In order to configure the number of shards of an index, we will need to configure the sharding_strategy.nbr_of_shards index property. So, to put it all together, our “Person” index, with 2 shards configured will look as follows:
spring.jpa.properties.hibernate.search.com.nullbeans.persistence.models.Person.sharding_strategy.nbr_of_shards = 2
We can eliminate the package name, and provide our own name by configuring the name of the index in the entity class as follows:
@Entity
@Indexed(index = "PersonIndex")
public class Person {
private long id;
.......
This renames the index to “PersonIndex”. We can now configure the index in the application properties as follows:
spring.jpa.properties.hibernate.search.PersonIndex.sharding_strategy.nbr_of_shards = 2
Note that if you would like to configure sharding for all your indecies, then you can just configure the “default” behavior of Hibernate search as follows:
spring.jpa.properties.hibernate.search.default.sharding_strategy.nbr_of_shards = 2
Now, let us fire up our Spring boot application. Automatically, Hibernate search should re-index our entity’s data. If everything went fine, you will find the following directories in your configured indexed directory.
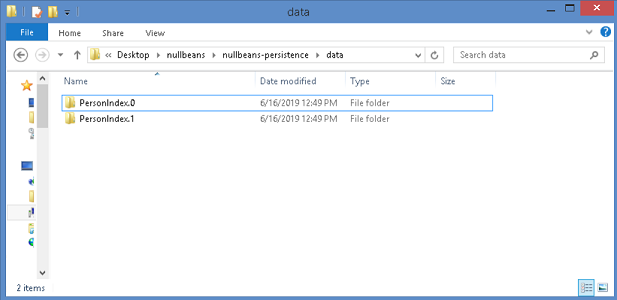
Please note that if you are not using Spring boot, then you will need to manually configure your JPA properites, either in your Persistence.xml file, your hibernate.properties file, etc. In that case, you can omit the “spring.jpa.properties” suffix as follows:
hibernate.search.PersonIndex.sharding_strategy.nbr_of_shards = 2
Important notes
As you have seen, configuring sharding is relatively a simple. However, the performance impact is not. Sharding is a very effective tool if your system resources are under-utilized. I highly recommend that you do some performance tests, trying out different settings, with and without sharding.
If you decided that sharding is for you, then you can start out with 2 shards and trying out the performance. If you experience an improvement in performance, then you can gradually increase the number of shards to 3, 4, 5, etc, until you find the sweet spot for your infrastructure setup.
Note that too many shards will degrade your performance. This is because Lucene will need to perform some system operations to decide which entry exists in which shard. So you also do not want to go overboard with the number of shards. Otherwise, Hibernate search will spend more time searching among the shards, than writing to them.
Leave a Reply
You must be logged in to post a comment.