In this post, we will discuss the principles of reactive programming, which problems is it trying to solve and discuss the basics of reactive programming in Java. This tutorial will focus on the usage of reactive programming in Java but the principles and ideas discussed in this tutorial can apply to other programming languages.
This post might be a long read, but if you have been confused about reactive programming, and not sure where to start, or if you have been having difficulties finding good sources of information about reactive programming in Java, then this tutorial can serve as a good start and can clarify lots of topics for you.
Which problem is Reactive programming trying to solve?
When I was first researching reactive programming, I would read definitions like “Reactive programming is a programming paradigm focused on data exchange and propagation”. However, such definitions miss the essence of the programming paradigm and doesn’t really explain much.
So let us try to simplify things by highlighting the difference between traditional imperative program execution and an async “reactive” one.
A program consists of a set of algorithmic steps that need to be executed in a specific order. In traditional program execution, a thread would execute these steps one at a time. Let us take a fast food restaurant visit as an example. In our setup, there is only one waiter at the cashier. The cashier is responsible for taking your order and packing your food once it is done cooking in the kitchen.
Each customer would walk to the counter to make their order. The waiter then passes the order to the kitchen, waits a few minutes till the food is ready and then packs it and gives it to the customer. The waiter would then start to take the order of the next customer after the first customer leaves.
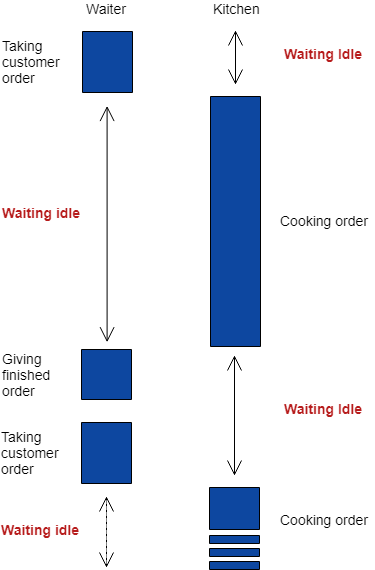
The problem with this approach is that it is not efficient due to wasted idle resource time. First, there is time wasted when the waiter is waiting for the kitchen to make the food. During that time, the waiter is not doing anything but waiting. Second, the kitchen is staying idle while the cashier is taking the order of the next customer.
In our example, the waiter represents a thread, while the kitchen can represent a database and the customer’s order could be user input. When a program executes in the traditional fashion, for example, when obtaining a REST request, the thread will first convert the request into a database query, sends it to the database, waits till the database replies, and once the reply is obtained, it is processed by the thread and a response is sent to the user.
While the thread is waiting for the database reply, this thread is blocked. This causes program execution to be inefficient and slow. While you could increase the number of threads available in your threadpool, each thread has it’s own memory overhead, and you are ultimately limited by the number of processing cores your platform has.
Also, if your application is dependent on an i/o system such as network resources or a database, then adding more threads will not improve performance issues caused by i/o latency.
In summary, the aim of reactive programming is to help your application remain responsive under different workloads and in different environmental conditions.
Reactive program execution
Reactive execution combines the principles of async execution and performs it in a specific pattern which we would define and control through “Reactive programming”.
Let us go back to the fast food restaurant example. In a reactive execution scenario, the waiter (the thread) will take the customer’s order (user input) and passes it to the kitchen (the database). But instead of waiting for the kitchen to finish the order, it will inform the customer (the subscriber) that they will be notified (via a subscription) once their order is complete. The waiter will then go on to take the order of the next customer and performs the same steps.
The waiter will keep passing customer orders until they obtain a notification from the kitchen that an order has been cooked. When there is a ready order, the waiter gives it to the customer and the customer’s request is completed.
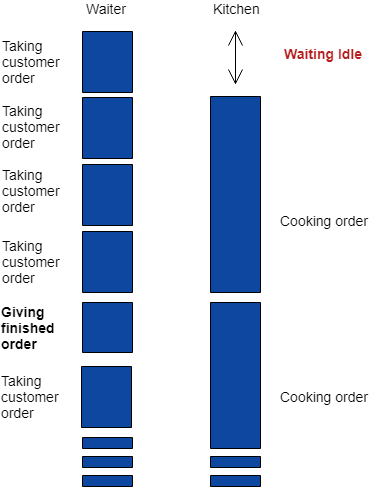
Using this approach improves our efficiency in two ways. First, the waiter is never idle, continuously taking customer orders. Second, the kitchen has a steady supply of orders to cook, making better usage of the kitchen resources. This also improves the customer’s experience as they are greeted and have their order taken much quicker, instead of waiting in a slow line with nobody giving them a response.
This is one of the biggest differences between traditional synchronous execution and an async reactive one. One can say that reactive programming can be used to improve the execution efficiency on a thread level.
What is Reactive programming
Now that we know how a reactive program executes, one can say that Reactive programming is a programming paradigm in which APIs, libraries and language features are used in a specific design pattern with the goal of achieving an async reactive program execution. We will explore the reactive design pattern in the next few sections.
The Reactive Manifesto
For an application to be reactive, it needs to possess specific properties. These properties have been defined in what is now called the “Reactive Manifesto”, and it what makes “reactive” applications different from just async ones.
For an application to be reactive, it needs to be:
- Responsive: The system should respond to requests in a timely manner. Responsive systems should have fast and consistent response times.
- Resilient: In case of failure, the system should still be responsive. For example, if an error occurs in on a website and the user tries to access that website, the website should reply to the user with a nice error page instead of just not replying at all.
- Elastic: An elasic system is one which can adapt to different workloads. For example, it can scale its resources up during peak load and scale down when the load is very low. An elastic system should remain responsive even under heavy load.
- Message Driven: Reactive systems utilize an asynchronous message driven communication mechanisms (think the waiter who told the customer that he will be notified when the order is ready). This allows more efficient resource usage and better fault isolation and tolerance. Imagine your system utilizes an unstable database that hangs randomly. If you were using a traditional blocking calls, each time one of your application threads would call the database and the database hangs, this thread will be blocked for a long time. This leaves less threads for the rest of your application to use. An async message driven communication works around such issues.
It is important to note that these four principles are only principles. No system is immune from failure or performance degradation. However, if your goal is to build a reactive system, then your system needs to adhere to these principles as much as possible.
The reactive manifesto is a common understanding of reactive systems developed by several individuals and organizations in the technology industry. You can read more about it here.
What is Back pressure
Back pressure is another fancy word for data flow rate control. It is deployed in order to improve the stability and integrity of the system.
Take for example an application that processes user queries. The system handles each request the user sends. However, if one user is sending too many queries too fast, they could slow down or crash the system and degrade the experience of other users (such as in denial of service attacks).
Back pressure attempts to solve this problem by limiting the number of operations that are allowed to be executed within a given amount of time (aka limiting the execution rate).
In reactive programming, there are multiple strategies for implementing back pressure, such as buffering or dropping requests. We will explore such strategies in another post.
Reactive programming in Java
If you googled reactive programming in Java, you will probably be confused by the differences in implementations and code in the different tutorials and articles on the internet. This is for a good reason.
Currently, there is no standard unified reactive API implementation in Java. There are currently numerous libraries that provide different implementations and tools to perform reactive programming.
From RxJava 1 and 2, the Java Flow API introduced in SDK 9, Reactive Streams, to Project Reactor (which is used by Spring) and Akka Streams, to name a few.
The important thing to keep in mind is that these frameworks are based on the same design pattern, with each of them providing more or less out of the box functionalities and convenience classes. We will explore some of these different libraries in later tutorial.
We will focus in this section on the basic design pattern that most of these frameworks are based upon. The choice of which library fits your project is ultimately up to you.
Let us start by defining the basic components of a reactive program, and then we will sum it up at the end to see how they all work together.
The Publisher
The publisher is simply the data producer. This is the component that produces the desired data for your system. In practical terms, this could be a database result, a twitter feed, a stock market quote feed, etc.
A publisher has no name… I mean many names. It depends on your choice of reactive library.
- Observable (RxJava) / Mono (Project Reactor): These are different names for publishers that produce no data (void). In the reactive streams specification, it is just called a publisher.
- Single (RxJava) / Mono (Project Reactor): These are different names for publishers that produce at most a single data item. In the reactive streams specification, it is called a publisher.
- Observable (RxJava) / Flux (Project Reactor): These are different names for publishers that produce multiple data items. In the reactive streams specification, it is still called a publisher.
The Subscriber
The subscriber “subscribes” to the publisher and is notified when new data is produced, when an error occurs, or when the publisher has completed the data production. Inside the subscriber is where the produced data is processed.
Luckily, the subscriber is called subscriber in both RxJava and Project Reactor.
The subscriber has three data channels. Each channel is signaled through one of the subscriber’s internal methods:
- OnNext: this method is called when one or more data items have been produced by the publisher.
- OnError: this method is called when an error occurs during the production of data by the publisher. Note that once the OnError method is called, no more data is produced by the publisher.
- OnComplete: this method is used to indicate that the publisher is completed the production of data, and that no more data will be produced.
Please note that the methods above can be called on either the caller thread or on a separate thread, depending on your configuration.
The last method that we should discuss is the OnSubscribe. This method is called once a subscription has been established. Note that this does not serve as a data channel. It is used to setup the subscriber and to request the first item from the subscription.
The Subscription
The Subscription is a contract between both the subscriber and a publisher. It can be used by the subscriber to request more items from the publisher, or to cancel the subscription to halt the receipt of more data.
The subscriber can request the next 1-n items from the publisher through the subscription’s request method. This is usually done inside the subscriber’s onSubscribe and onNext methods.
The Processor
The Processor is a reactive entity that acts as both a subscriber and a publisher. This means that it can consume items produced by a publisher, and it can publish data itself.
Processors are usually installed between publishers and subscribers for processing intermediate data items. For example, you can create a processor which will perform spelling corrections to all words produced by the publisher. In this case, the processor acts as a subscriber. The processor will then publish the corrected words to its subscribers, acting as a publisher.
Summing it up all together
A picture says a thousand words. So let us take a look at the next diagram.
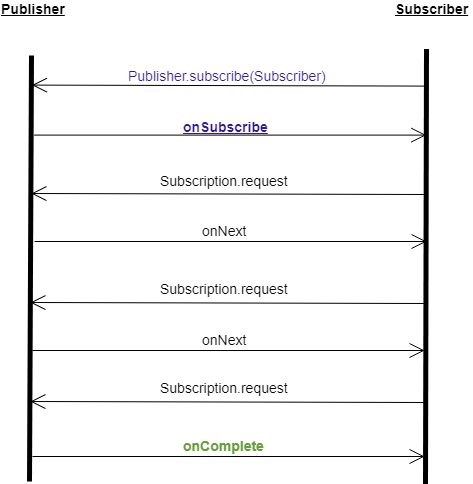
In a basic reactive program execution, it all starts with a subscriber subscribing to a publisher. Once a subscription has been created successfully between the publisher and the subscriber, the subscriber requests the data using the subscription’s request method.
When the publisher publishes new data, the subscriber’s onNext method is called. The subscriber can then request more data or cancel the subscription. In our example, the subscriber requests more data.
Once the publisher has no more data to publish, the subscriber’s onComplete method is called, indicating the completion and the end of the contract (subscription).
Summary
Reactive programming has been there for a while. However, the tech industry has finally taken notice of this design pattern, due to demand for better response times from systems, more strict reliability requirements and the rise of micro service architectures.
In this tutorial, we discussed the advantages of using reactive programming in i/o scenarios in order to take better advantage of available system resources and to improve application response times.
Leave a Reply
You must be logged in to post a comment.